Blogs
The latest cybersecurity trends, best practices, security vulnerabilities, and more
ARCHIVED STORY
Introduction and Application of Model Hacking
By Steve Povolny · Febraury 19, 2020
Catherine Huang, Ph.D., and Shivangee Trivedi contributed to this blog.
The term “Adversarial Machine Learning” (AML) is a mouthful! The term describes a research field regarding the study and design of adversarial attacks targeting Artificial Intelligence (AI) models and features. Even this simple definition can send the most knowledgeable security practitioner running! We’ve coined the easier term “model hacking” to enhance the reader’s comprehension of this increasing threat. In this blog, we will decipher this very important topic and provide examples of the real-world implications, including findings stemming from the combined efforts of McAfee’s Advanced Analytic Team (AAT) and Advanced Threat Research (ATR) for a critical threat in autonomous driving.
1. First, the Basics
AI is interpreted by most markets to include Machine Learning (ML), Deep Learning (DL), and actual AI, and we will succumb to using this general term of AI here. Within AI, the model – a mathematical algorithm that provides insights to enable business results – can be attacked without knowledge of the actual model created. Features are those characteristics of a model that define the output desired. Features can also be attacked without knowledge of the features used! What we have just described is known as a “black box” attack in AML – not knowing the model and features – or “model hacking.” Models and/or features can be known or unknown, increasing false positives or negatives, without security awareness unless these vulnerabilities are monitored and ultimately protected and corrected.
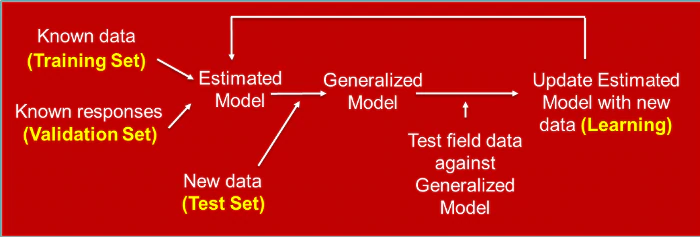
In the feedback learning loop of AI, recurrent training of the model occurs in order to comprehend new threats and keep the model current (see Figure 1). With model hacking, the attacker can poison the Training Set. However, the Test Set can also be hacked, causing false negatives to increase, evading the model’s intent and misclassifying a model’s decision. Simply by perturbating – changing the magnitudes of a few features (such as pixels for images), zeros to ones/ones to zeros, or removing a few features – the attacker can wreak havoc in security operations with disastrous effects. Hackers will continue to “ping” unobtrusively until they are rewarded with nefarious outcomes – and they don’t even have to attack with the same model that we are using initially!
2. Digital Attacks of Images and Malware
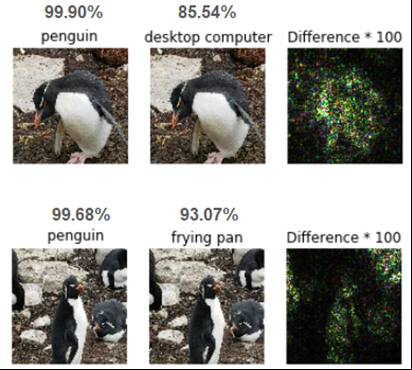
Hackers’ goals can be targeted (specific features and one specific error class) or non-targeted (indiscriminate classifiers and more than one specific error class), digital (e.g., images, audio) or physical (e.g., speed limit sign). Figure 2 shows a rockhopper penguin targeted digitally. A white-box evasion example (we knew the model and the features), a few pixel changes and the poor penguin in now classified as a frying pan or a computer with excellent accuracy.
While most current model hacking research focuses on image recognition, we have investigated evasion attacks and mitigation methods for malware detection and static analysis. We utilized DREBIN[1], an Android malware dataset, and replicated the results of Grosse, et al., 2016[2]. Utilizing 625 malware samples highlighting FakeInstaller, and 120k benign samples and 5.5K malware, we developed a four-layer deep neural network with about 1.5K features (see Figure 3).However, following an evasion attack with only modifying less than 10 features, the malware evaded the neural net nearly 100%. This, of course, is a concern to all of us.

"migrar a Trellix Endpoint Security"
Utilice conjuntos de comillas para realizar varias búsquedas:
"seguridad de endpoints" "Windows"
Se ignoran los signos de puntuación y los caracteres especiales.
Evite utilizar los siguientes caracteres: `, ~, :, @, #, $, %, ^, &, =, +, <, >, (, )
El motor de búsqueda ignora mayúsculas y minúsculas:
Seguridad de endpoints, seguridad de endpointsy SEGURIDAD DE ENDPOINTS tendrán los mismos resultados.