Blogs
The latest cybersecurity trends, best practices, security vulnerabilities, and more
ARCHIVED STORY
Introduction and Application of Model Hacking
By Steve Povolny · Febraury 19, 2020
Catherine Huang, Ph.D., and Shivangee Trivedi contributed to this blog.
The term “Adversarial Machine Learning” (AML) is a mouthful! The term describes a research field regarding the study and design of adversarial attacks targeting Artificial Intelligence (AI) models and features. Even this simple definition can send the most knowledgeable security practitioner running! We’ve coined the easier term “model hacking” to enhance the reader’s comprehension of this increasing threat. In this blog, we will decipher this very important topic and provide examples of the real-world implications, including findings stemming from the combined efforts of McAfee’s Advanced Analytic Team (AAT) and Advanced Threat Research (ATR) for a critical threat in autonomous driving.
1. First, the Basics
AI is interpreted by most markets to include Machine Learning (ML), Deep Learning (DL), and actual AI, and we will succumb to using this general term of AI here. Within AI, the model – a mathematical algorithm that provides insights to enable business results – can be attacked without knowledge of the actual model created. Features are those characteristics of a model that define the output desired. Features can also be attacked without knowledge of the features used! What we have just described is known as a “black box” attack in AML – not knowing the model and features – or “model hacking.” Models and/or features can be known or unknown, increasing false positives or negatives, without security awareness unless these vulnerabilities are monitored and ultimately protected and corrected.
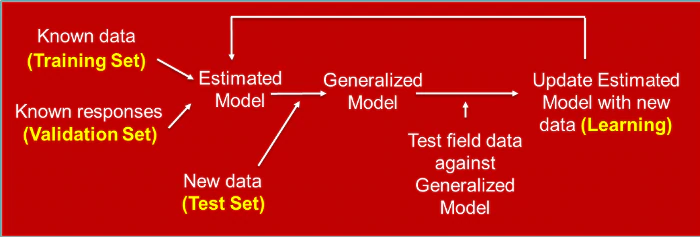
In the feedback learning loop of AI, recurrent training of the model occurs in order to comprehend new threats and keep the model current (see Figure 1). With model hacking, the attacker can poison the Training Set. However, the Test Set can also be hacked, causing false negatives to increase, evading the model’s intent and misclassifying a model’s decision. Simply by perturbating – changing the magnitudes of a few features (such as pixels for images), zeros to ones/ones to zeros, or removing a few features – the attacker can wreak havoc in security operations with disastrous effects. Hackers will continue to “ping” unobtrusively until they are rewarded with nefarious outcomes – and they don’t even have to attack with the same model that we are using initially!
2. Digital Attacks of Images and Malware
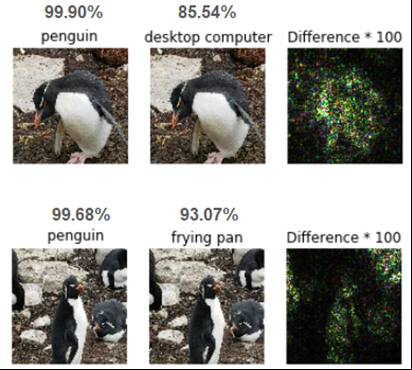
Hackers’ goals can be targeted (specific features and one specific error class) or non-targeted (indiscriminate classifiers and more than one specific error class), digital (e.g., images, audio) or physical (e.g., speed limit sign). Figure 2 shows a rockhopper penguin targeted digitally. A white-box evasion example (we knew the model and the features), a few pixel changes and the poor penguin in now classified as a frying pan or a computer with excellent accuracy.
While most current model hacking research focuses on image recognition, we have investigated evasion attacks and mitigation methods for malware detection and static analysis. We utilized DREBIN[1], an Android malware dataset, and replicated the results of Grosse, et al., 2016[2]. Utilizing 625 malware samples highlighting FakeInstaller, and 120k benign samples and 5.5K malware, we developed a four-layer deep neural network with about 1.5K features (see Figure 3).However, following an evasion attack with only modifying less than 10 features, the malware evaded the neural net nearly 100%. This, of course, is a concern to all of us.

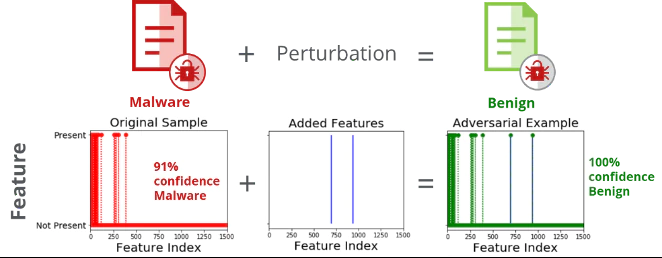
Using the CleverHans[1] open-source library’s Jacobian Saliency Map Approach (JSMA) algorithm, we generated perturbations creating adversarial examples. Adversarial examples are inputs to ML models that an attacker has intentionally designed to cause the model to make a mistake[1]. The JSMA algorithm needs only a minimum number of features need to be modified. Figure 4 demonstrates the original malware sample (detected as malware with 91% confidence). After adding just two API calls in a white-box attack, the adversarial example is now detected with 100% confidence as benign. Obviously, that can be catastrophic!
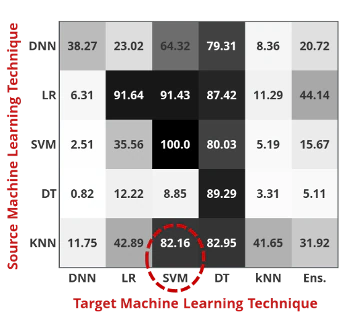
In 2016, Papernot[5] demonstrated that an attacker doesn’t need to know the exact model that is utilized in detecting malware. Demonstrating this theory of transferability in Figure 5, the attacker constructed a source (or substitute) model of a K-Nearest Neighbor (KNN) algorithm, creating adversarial examples, which targeted a Support Vector Machine (SVM) algorithm. It resulted in an 82.16% success rate, ultimately proving that substitution and transferability of one model to another allows black-box attacks to be, not only possible, but highly successful.
In a black-box attack, the DREBIN Android malware dataset was detected 92% as malware. However, using a substitute model and transferring the adversarial examples to the victim (i.e., source) system, we were able to reduce the detection of the malware to nearly zero; Another catastrophic example!
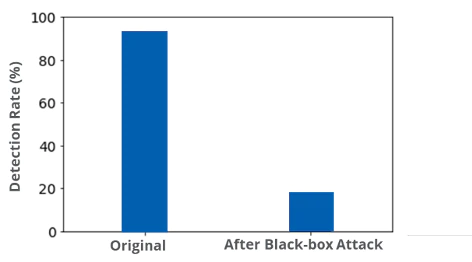
3. Physical Attack of Traffic Signs
While malware represents the most common artifact deployed by cybercriminals to attack victims, numerous other targets exist that pose equal or perhaps even greater threats. Over the last 18 months, we have studied what has increasingly become an industry research trend: digital and physical attacks on traffic signs. Research in this area dates back several years and has since been replicated and enhanced in numerous publications. We initially set out to reproduce one of the original papers on the topic, and built a highly robust classifier, using an RGB (Red Green Blue) webcam to classify stop signs from the LISA[6] traffic sign data set. The model performed exceptionally well, handling lighting, viewing angles, and sign obstruction. Over a period of several months, we developed model hacking code to cause both untargeted and targeted attacks on the sign, in both the digital and physical realms. Following on this success, we extended the attack vector to speed limit signs, recognizing that modern vehicles increasingly implement camera-based speed limit sign detection, not just as input to the Heads-Up-Display (HUD) on the vehicle, but in some cases, as input to the actual driving policy of the vehicle. Ultimately, we discovered that minuscule modifications to speed limit signs could allow an attacker to influence the autonomous driving features of the vehicle, controlling the speed of the adaptive cruise control! For more detail on this research, please refer to our extensive blog post on the topic.
4. Detecting and Protecting Against Model Hacking
The good news is that much like classic software vulnerabilities, model hacking is possible to defend against, and the industry is taking advantage of this rare opportunity to address the threat before it becomes of real value to the adversary. Detecting and protecting against model hacking continues to develop with many articles published weekly.
Detection methods include ensuring that all software patches have been installed, closely monitoring drift of False Positives and False Negatives, noting cause and effect of having to change thresholds, retraining frequently, and auditing decay in the field (i.e., model reliability). Explainable AI (“XAI”) is being examined in the research field for answering “why did this NN make the decision it did?” but can also be applied to small changes in prioritized features to assess potential model hacking. In addition, human-machine teaming is critical to ensure that machines are not working autonomously and have oversight from humans-in-the-loop. Machines currently do not understand context; however, humans do and can consider all possible root causes and mitigations of a nearly imperceptible shift in metrics.
Protection methods commonly employed include many analytic solutions: Feature Squeezing and Reduction, Distillation, adding noise, Multiple Classifier System, Reject on Negative Impact (RONI), and many others, including combinatorial solutions. There are pros and cons of each method, and the reader is encouraged to consider their specific ecosystem and security metrics to select the appropriate method.
5. Model Hacking Threats and Ongoing Research
While there has been no documented report of model hacking in the wild yet, it is notable to see the increase of research over the past few years: from less than 50 literature articles in 2014 to over 1500 in 2020. And it would be ignorant of us to assume that sophisticated hackers aren’t reading this literature. It is also notable that, perhaps for the first time in cybersecurity, a body of researchers have proactively developed the attack, detection, and protection against these unique vulnerabilities.
We will continue to add to the greater body of knowledge of model hacking attacks as well as ensure the solutions we implement have built-in detection and protection. Our research excels in targeting the latest algorithms, such as GANS (Generative Adversarial Networks) in malware detection, facial recognition, and image libraries. We are also in process of transferring traffic sign model hacking to further real-world examples.
Lastly, we believe McAfee leads the security industry in this critical area. One aspect that sets McAfee apart is the unique relationship and cross-team collaboration between ATR and AAT. Each leverages its unique skillsets; ATR with in-depth and leading-edge security research capabilities, and AAT, through its world-class data analytics and artificial intelligence expertise. When combined, these teams are able to do something few can; predict, research, analyze and defend against threats in an emerging attack vector with unique components, before malicious actors have even begun to understand or weaponize the threat.
For further reading, please see any of the references cited, or “Introduction to Adversarial Machine Learning” at https://mascherari.press/introduction-to-adversarial-machine-learning/
[1] Courtesy of Technische Universitat Braunschweig.
[1] Grosse, Kathrin, Nicolas Papernot, et al. ”Adversarial Perturbations Against Deep Neural Networks for Malware Classification” Cornell University Library. 16 Jun 2016.
[3] Cleverhans: An adversarial example library for constructing attacks, building defenses, and benchmarking both located at https://github.com/tensorflow/cleverhans.
[4] Goodfellow, Ian, et al. “Generative Adversarial Nets” https://papers.nips.cc/paper/5423-generative-adversarial-nets.pdf.
[5] Papernot, Nicholas, et al. “Transferability in Machine Learning: from Phenomena to Black-Box Attacks using Adversarial Samples” https://arxiv.org/abs/1605.07277.
[6] LISA = Laboratory for Intelligent and Safe Automobiles
RECENT NEWS
-
Mar 02, 2026
Trellix strengthens executive leadership team to accelerate cyber resilience vision
-
Feb 10, 2026
Trellix SecondSight actionable threat hunting strengthens cyber resilience
-
Dec 16, 2025
Trellix NDR Strengthens OT-IT Security Convergence
-
Dec 11, 2025
Trellix Finds 97% of CISOs Agree Hybrid Infrastructure Provides Greater Resilience
-
Oct 29, 2025
Trellix Announces No-Code Security Workflows for Faster Investigation and Response
RECENT STORIES
Get the latest
Stay up to date with the latest cybersecurity trends, best practices, security vulnerabilities, and so much more.
Zero spam. Unsubscribe at any time.